The Problem
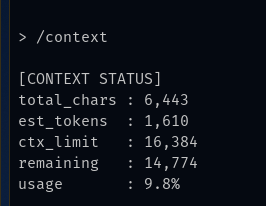
AI systems forget previous sessions, context windows are limited, and conversations reset or degrade over time. Local models have no built-in memory, so every interaction starts from scratch.
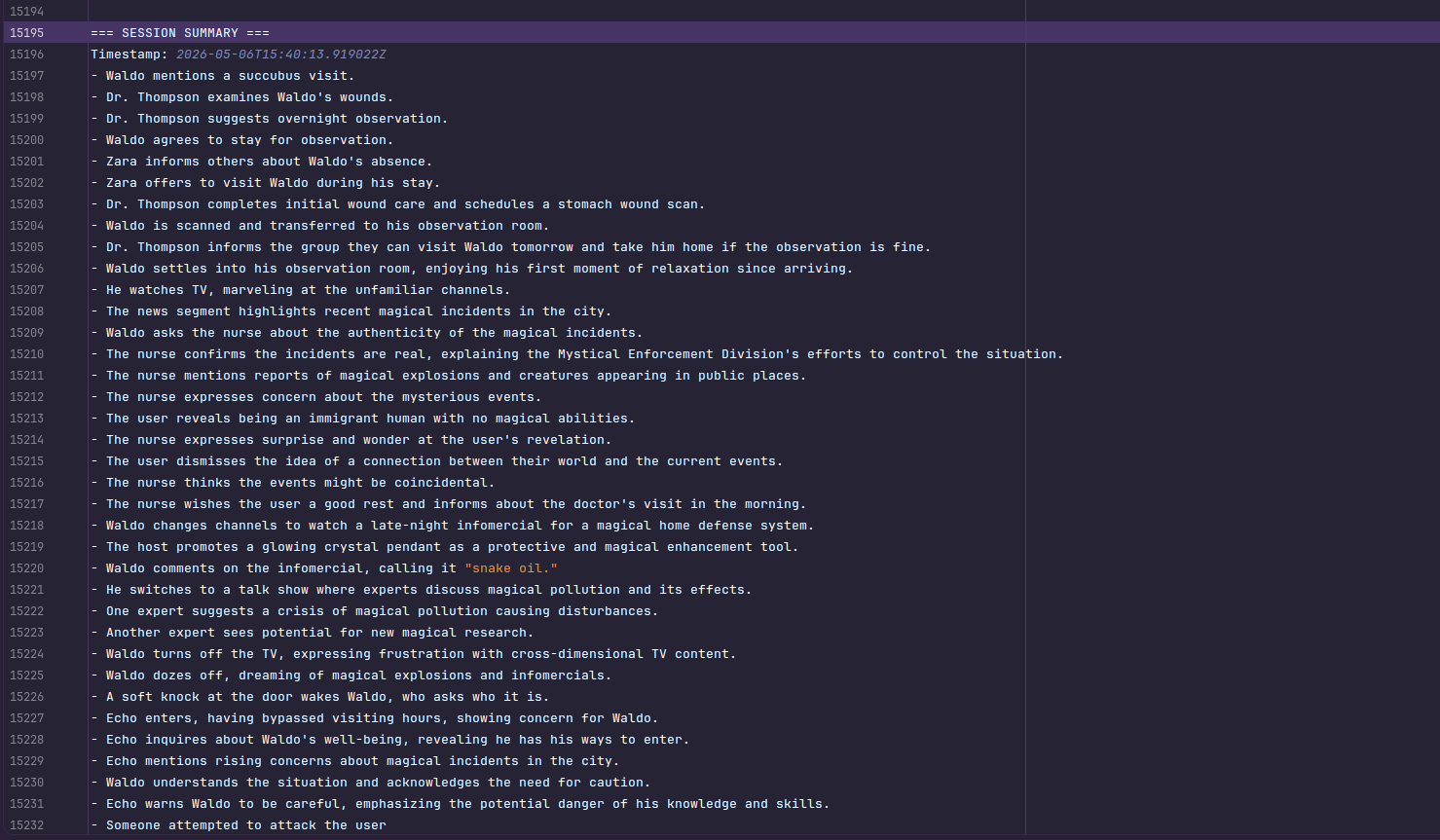
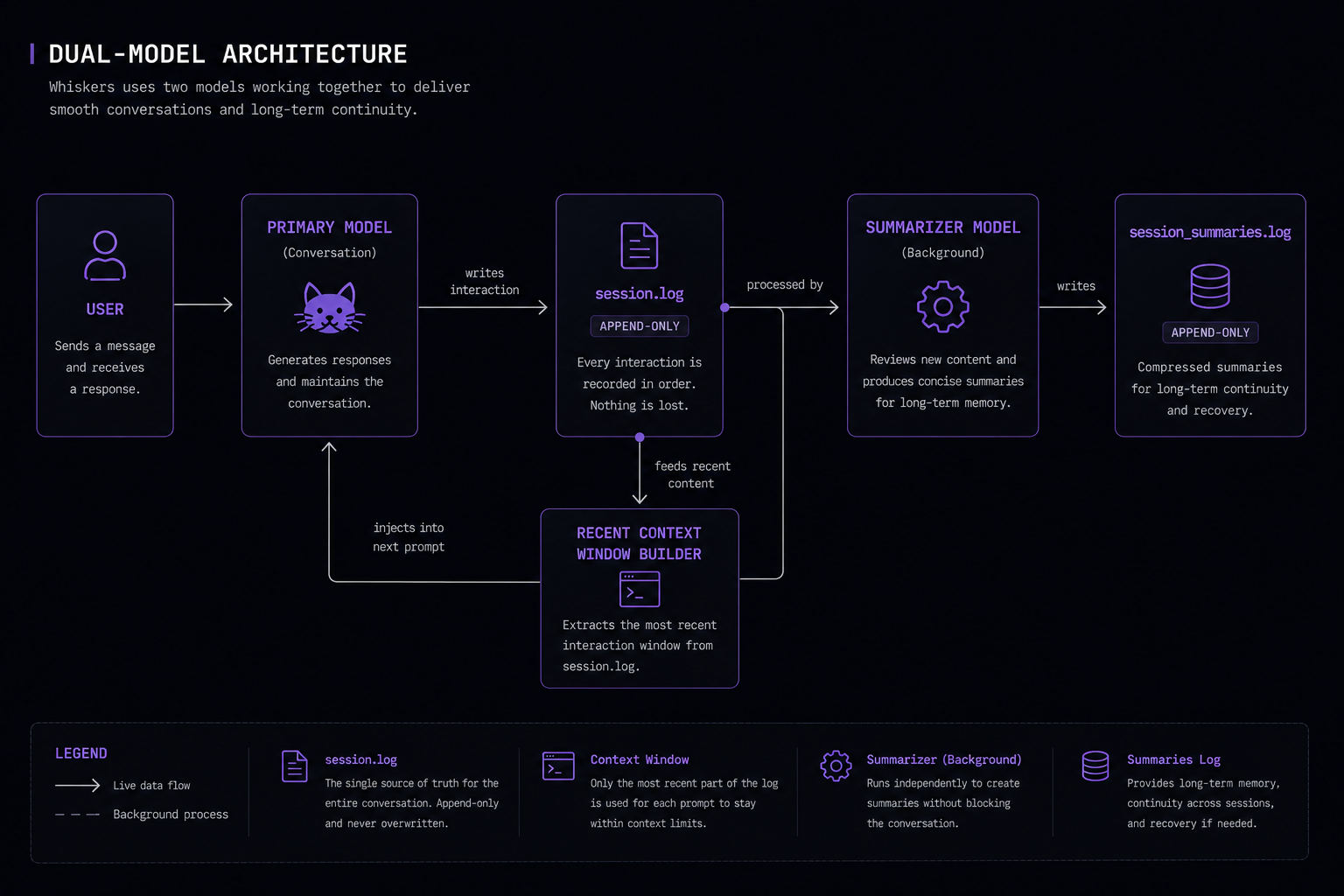
Whiskers adds a runtime around the model: persistent logs, bounded context rebuilding, commands, and optional summaries for longer-running work.